
예제로 배우는 크롤링:닛신 라멘 뮤지엄 견학 캔슬 알람 보내기 (2)


ScrapingBee란?
ScrapingBee에 대해서는 아래 페이지를 참조해주세요.
[프리뷰] ScrapingBee: 심플한 웹 스크래핑 통합솔루션
이 블로그에서는 다양한 웹 스크래핑 툴을 소개해 왔습니다. 1인 개발을 하다 보면 서비스를 구축하는 것보다 서비스의 콘텐츠를 풍부하게 하는 것이 더 어려운 경우가 많고 웹 스크래핑은 이런 문제를 해결하는 좋은 방법이기 때문입니다. 그럼 지금까지 소개한 솔루션과 ScrapingBee는 무엇이 다를까요? 그리고 어떤 사용자에게 적합한 솔루션일까요? 이번 포스트에서 주요 특징과 간단한 사용법을
ScrapingBee 설정 방법
ScrapingBee에서 'HTML Request Builder' 메뉴를 클릭하여 신규 요청 창을 열고, 아래와 같이 설정합니다.
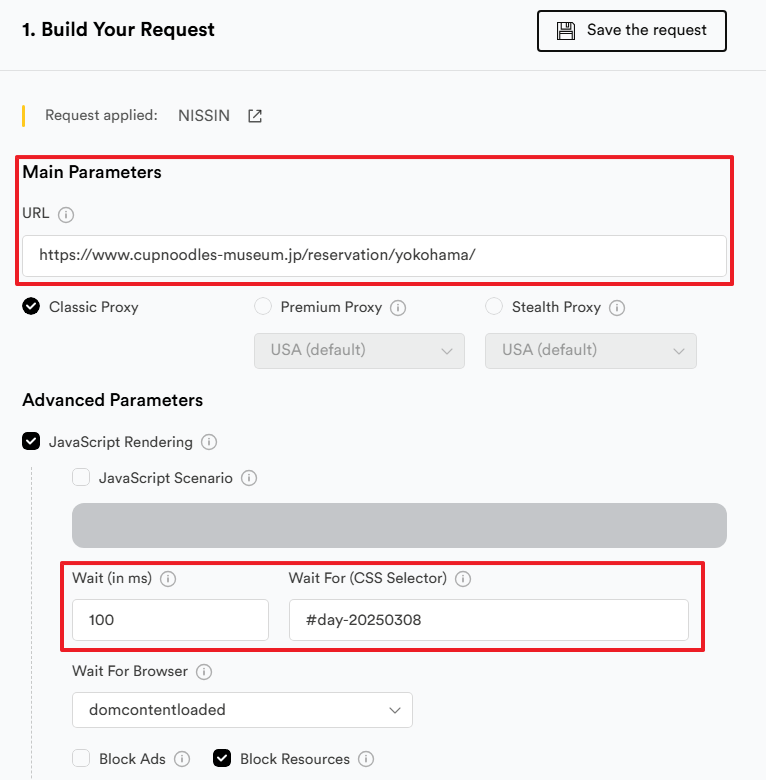
- Main Parameters: 웹 크롤링 대상 페이지의 URL을 입력하는 부분입니다.
- Wait (in ms): 웹 페이지가 로딩되기까지 기다릴 시간을 입력하는 부분입니다. 크롤링 대상 페이지에 맞춰서 설정하시면 됩니다.
- Wait For (CSS Selector): 만약 크롤링 대상 페이지가 일단 페이지를 로딩한 후 JS 등을 사용하여 추가 정보를 불러오는 타입일 경우, 특정한 DOM 요소가 로드될 때까지 기다리기 위한 명령입니다. 위의 예에서는
#day-20250308이라는 ID를 가지고 있는 태그가 로드될 때까지 기다리고 있습니다. 크롤링하려는 페이지에 맞춰서 설정하시기 바랍니다. 만약 CSS 셀렉터에 대해 알고 싶으신 분은 다른 사이트를 참조해 주세요.
위의 설정으로도 크롤링이 가능합니다만, 이대로라면 해당 페이지에 존재하는 모든 데이터를 읽어 오게 되기 때문에 불필요한 데이터가 과도하게 포함될 수 있습니다.
이 경우 아래 설정을 통해 원하는 요소만 크롤링하는 것이 가능합니다.
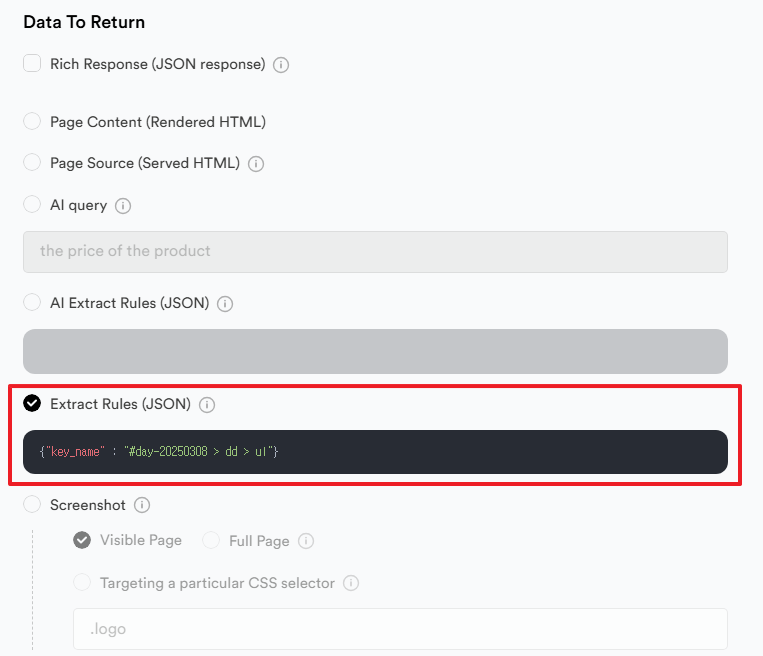
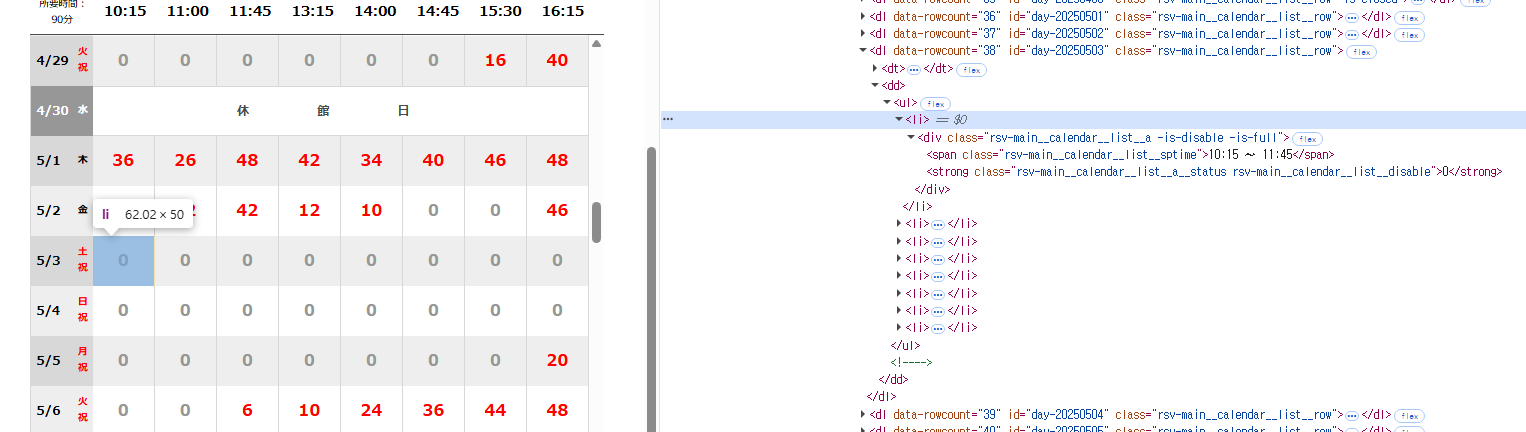
JSON 형식으로 셀렉터를 사용하여 데이터를 추출하고 싶은 위치를 지정합니다. 데이터를 추출할 위치는 크롬 브라우저의 개발자 도구를 이용하면 간단히 확인할 수 있습니다.
위의 설정을 완료하면, ScrapingBee의 코드 생성 부분에 아래와 같은 형식의 URL이 출력됩니다. (설정 내용에 따라 세부적인 내용은 달라질 수 있습니다)
cURL 형식의 URL 중 URL 부분을 웹 브라우저에 붙여넣으면 결과값이 제대로 취득되는지 확인할 수 있습니다.
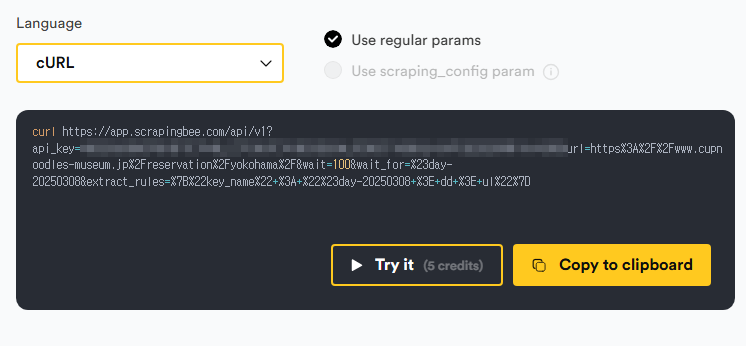
이렇게 해서 Make.com의 HTTP 모듈에 입력하기 위한 URL 준비가 끝났습니다.
다음 글에서는 이를 통해 얻어진 정보를 필터링하는 과정을 진행하도록 하겠습니다.
예제로 배우는 크롤링:닛신 라멘 뮤지엄 견학 캔슬 알람 보내기 (3)
지금까지의 과정을 통해 Make.com의 시나리오에 넣기 위한 모든 정보가 모였습니다.
이제 Make의 시나리오 설정을 완료하여 크롤링을 캐시하는 단계까지 진행해 보도록 하겠습니다. 우선, 이전에 제작한 시나리오의 HTTP 모듈에는 아래와 같이 ScrapingBee에서 얻은 URL을 입력합니다. 이를 통해 시나리오가 실행되면 HTTP 모듈이 자동으로 작동하고, 해당 URL에 접속하게 되어 ScrapingBee를 경유하여 원하는 장소의
