
[프리뷰] ScraperAPI: CAPTCHA와 VPN 신경 쓰지 않고 웹 크롤링을 하고 싶다면


"창과 방패: 사이트 운영자와 웹 크롤러의 끝나지 않는 전쟁"
웹 크롤링을 하다 보면 늘 마주치는 문제가 있습니다. 바로 웹 퍼블리셔(홈페이지 운영자)가 설정해 놓은 크롤링 방지 도구들(CAPTCHA, IP 차단 등)입니다.
힘들게 홈페이지 구조를 분석하고 크롤링 설정을 완료해도, 막상 실행하려고 하면 여지없이 튀어나오는 방어 체계에 크롤러들은 큰 어려움을 겪는데요.
어쩌면 ScraperAPI가 이 문제를 해결할 수 있을지도 모릅니다.
ScraperAPI의 서비스
웹 퍼블리셔들이 현재 크롤링을 막기 위해 사용하는 방법은 크게 세 가지로 나뉩니다:
- 로봇에 의한 접근 제한 (CAPTCHA 등)
- 액세스 위치 제한
- 접속 빈도 제한
ScraperAPI는 위와 같은 방어 체계를 무력화하기 위해 다음과 같은 서비스를 제공합니다:
- 머신러닝 기술을 활용한 CAPTCHA 우회
- 자체 운영하는 수많은 프록시 서버를 통해 IP를 자동으로 변경
물론 기존에도 CAPTCHA 우회 서비스나 프록시 서버 제공 도구는 존재했지만, 이를 하나씩 설정하는 것은 쉽지 않은 작업입니다.
이전에는 CAPTCHA 라이브러리를 설치하고 프록시 서버렌털 서비스를 따로 계약한뒤 크롤러와 합쳐서 직접 운영해야 했지요.
ScraperAPI는 이 모든 기능을 올인원 솔루션으로 제공하기 때문에 사용자는 원하는 홈페이지의 URL만 입력하면 크롤링 결과를 바로 얻을 수 있습니다.
사용소감
특정한 목적에 있어서 ScraperAPI는 상당히 만족도가 높은 플랫폼이었습니다.
ScraperAPI는 설정 시 여러 데이터 템플릿을 제공하는데요.
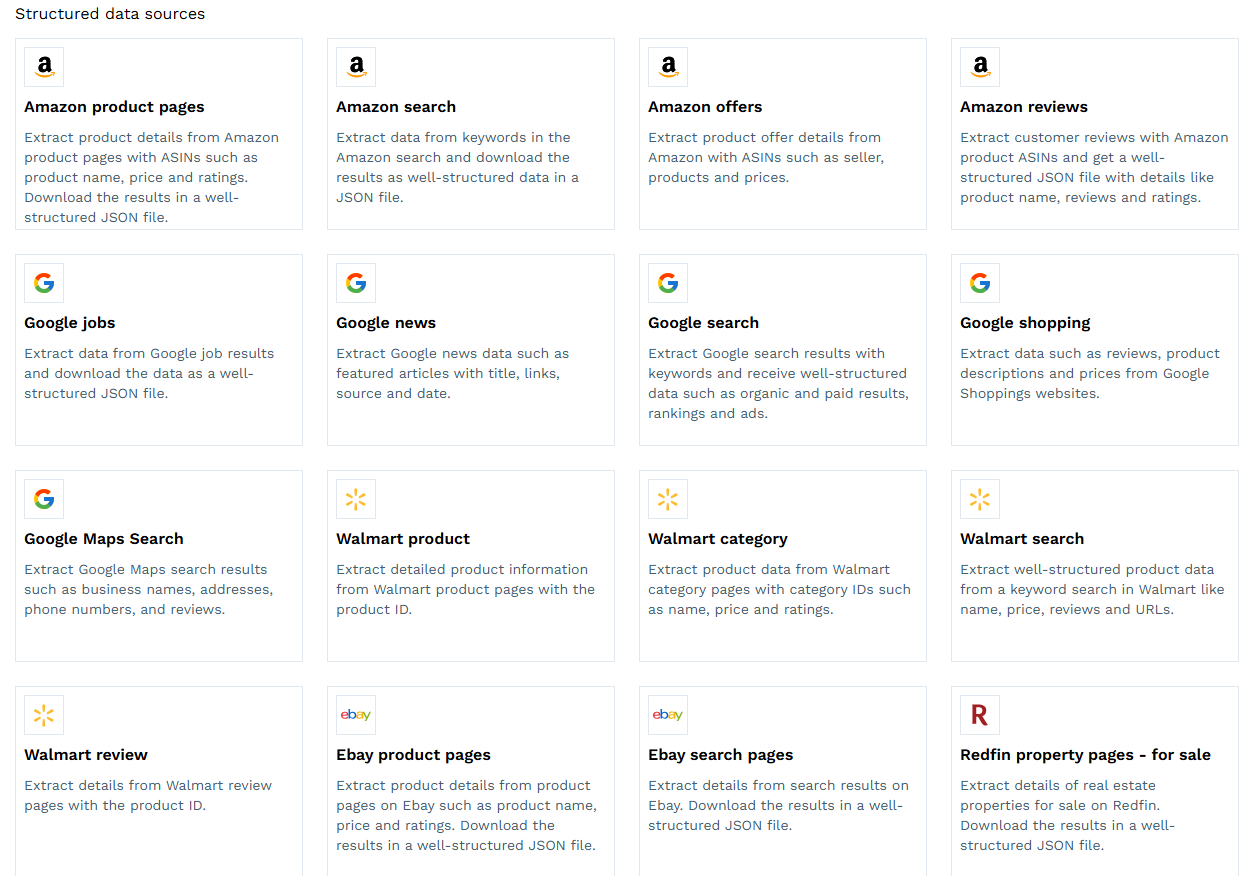
이 템플릿을 이용한 크롤링 작업에서는 ScraperAPI가 거의 완벽하게 작동했습니다. 뿐만 아니라, 크롤링한 데이터를 정리하여 CSV 형식으로 출력해주는 기능도 제공되기 때문에 매우 만족스러웠습니다.
다만, 템플렛화 되어있지 않는 사이트를 크롤링 할 경우 CAPTCHA 우회가 기대대로 작동하지 않는 경우가 있었습니다. 일단 서포트 페이지에는 CAPTCHA 우회가 제대로 작동하지 않는 경우 연락하면 제대로 동작하도록 업데이트를 해준다는 내용이 있었습니다만 범용성적인 측면에서 아직 완벽한 솔루션이라고는 할수 없었습니다.
총평
현시점에서 ScraperAPI는 Amazon, Google, Walmart, eBay, Redfin에 대한 템플릿을 제공하고 있고 이 사이트의 크롤링을 희망하시는 분이시라면 상당히 적합한 툴이라고 생각됩니다.
특히나 이러한 대형 사이트는 사이트 구조가 자주 바뀌기 때문에 직접 크롤러를 개발하면, 사이트 업데이트마다 코드를 수정해야 하는 번거로움이 있는데 이 부분을 ScraperAPI에서 해준다는 점은 큰 메리트 라고 생각합니다.
아쉬운점은 현재 제공되고 있는 템플릿 사이트 들이 미국에서 서비스중인 사이트에 치중되어 있다는 점입니다. 차후 각 나라별로 이용자가 많은 사이트 들이 추가 된다면 더욱 솔루션의 가치가 높아지리라 예상됩니다.
아직 확신이 없으신가요?
그렇다면 일단 한번 가입해보시는건 어떨까요? 다행이 ScraperAPI는 꽤나 넉넉한 무료 크레딧을 제공합니다. 일단 테스트 해보세요.